Biometrics Northwest LLC
Performing Data Analysis and Modeling
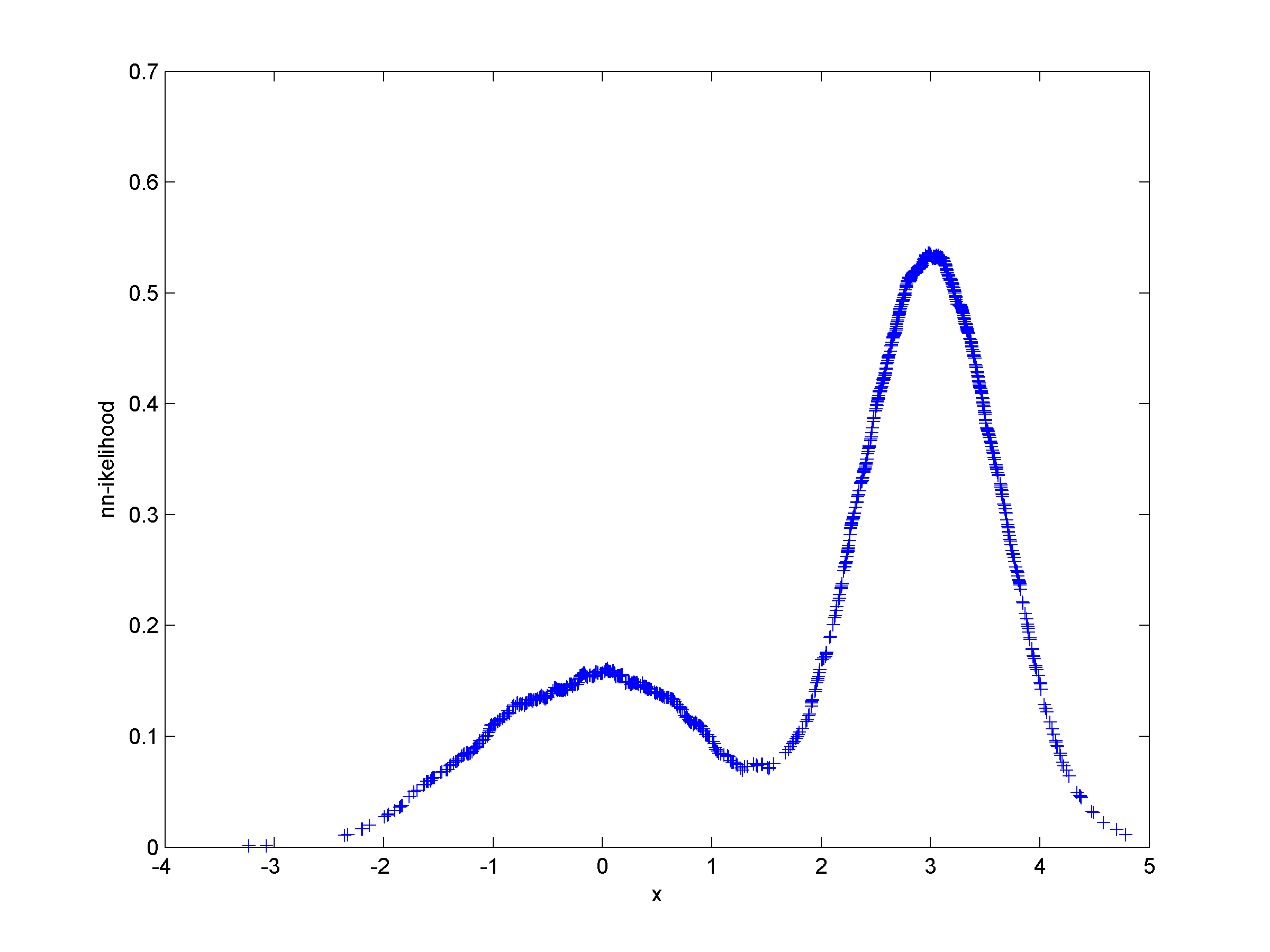
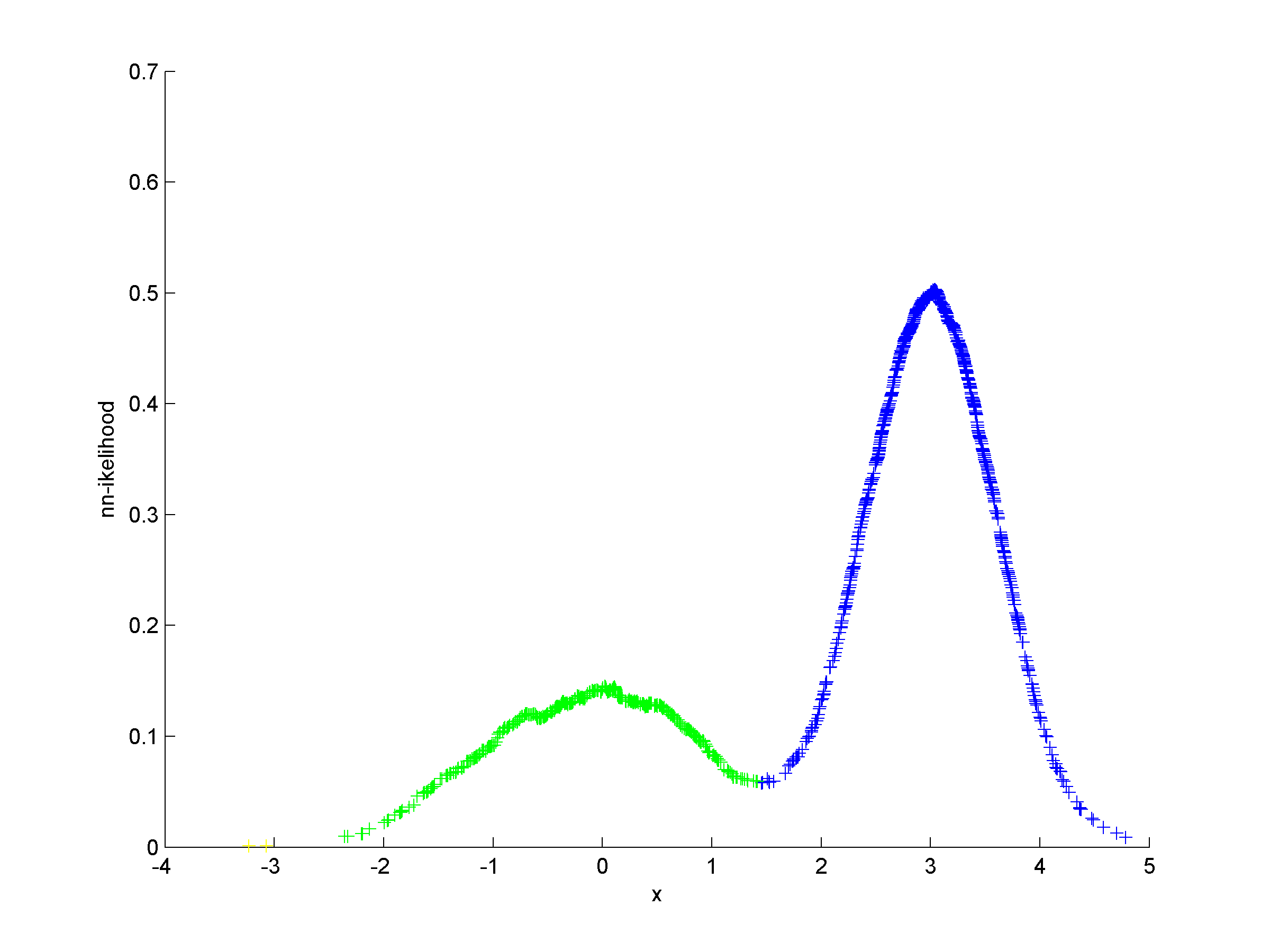
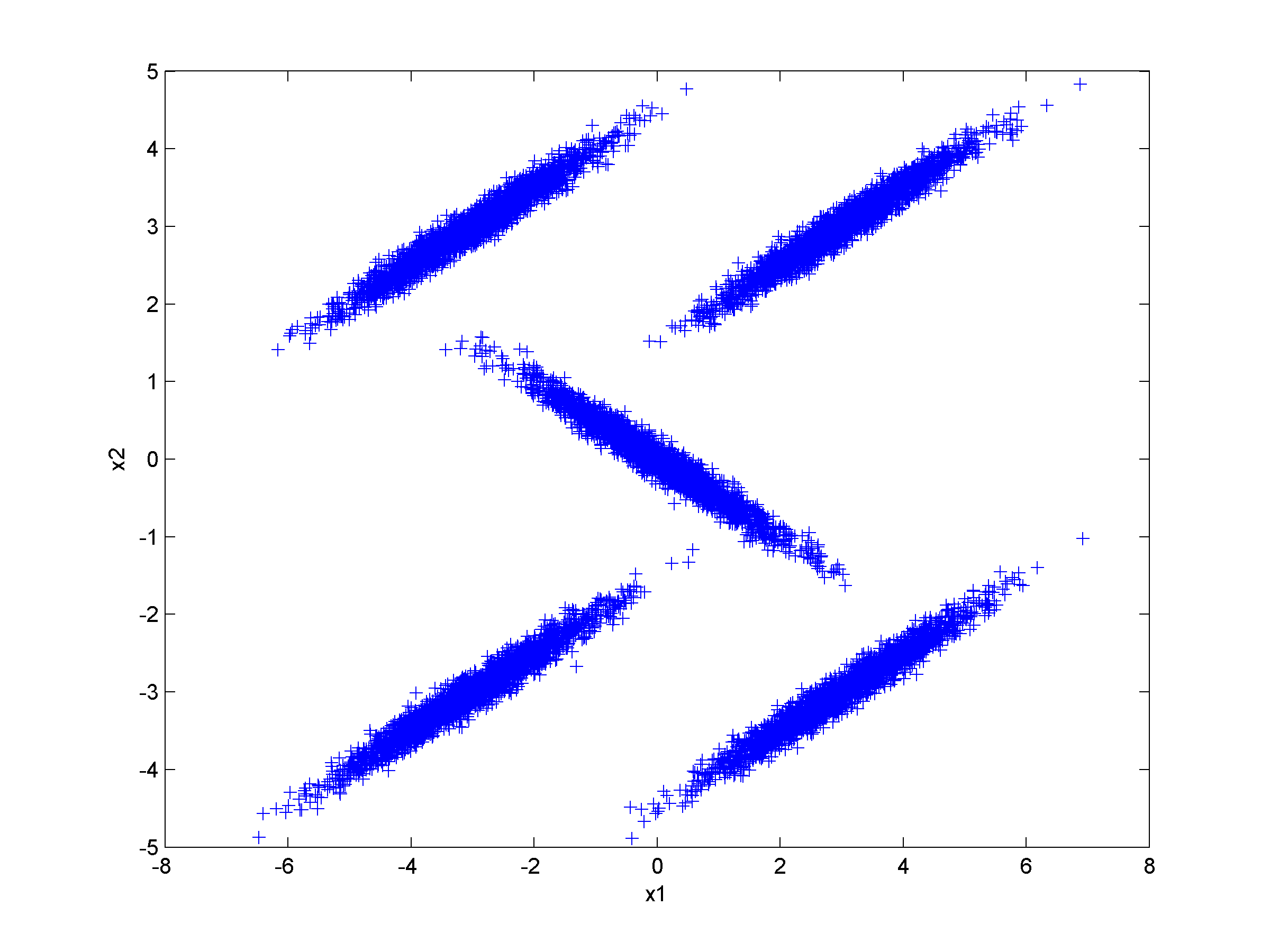
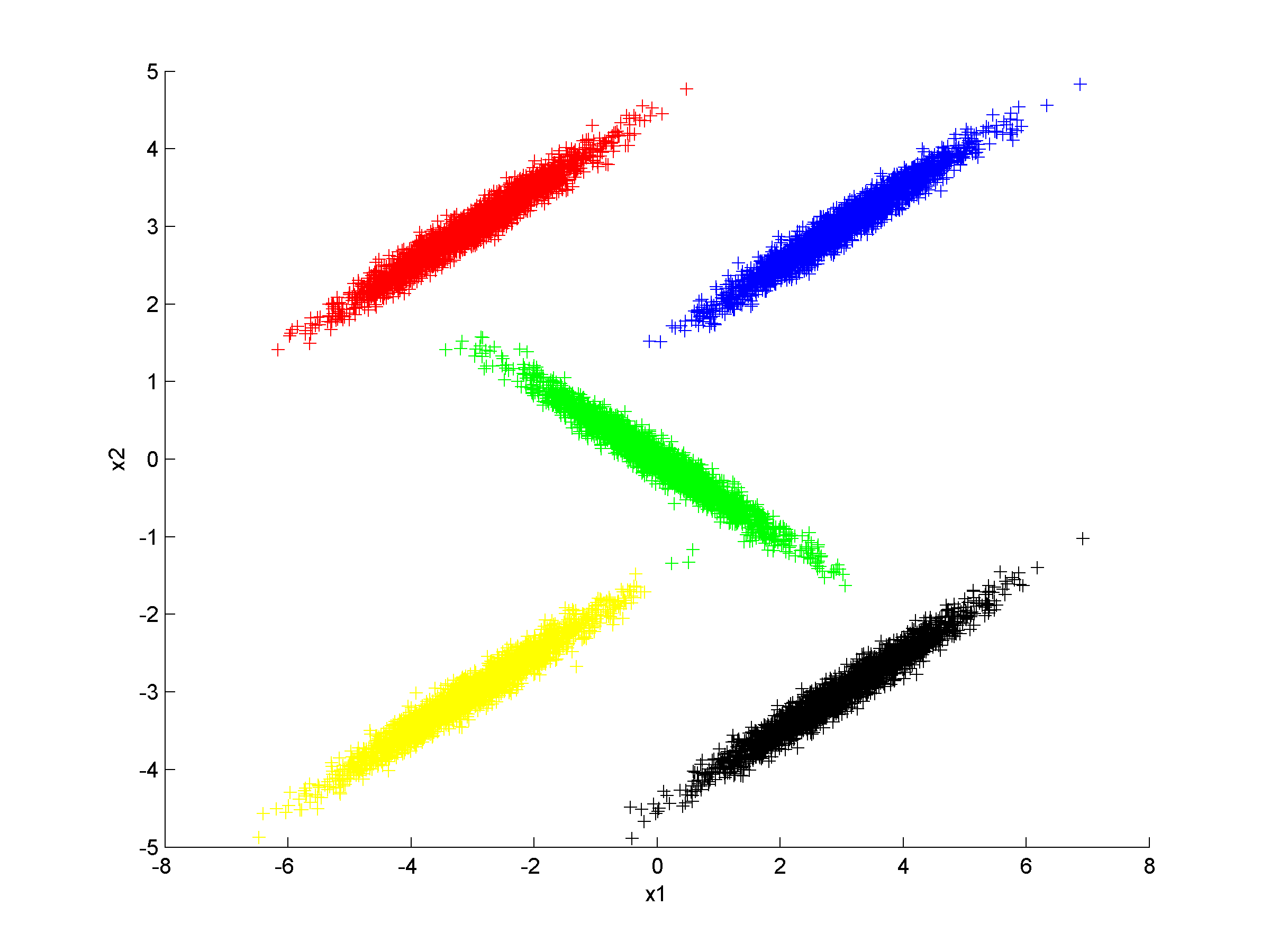
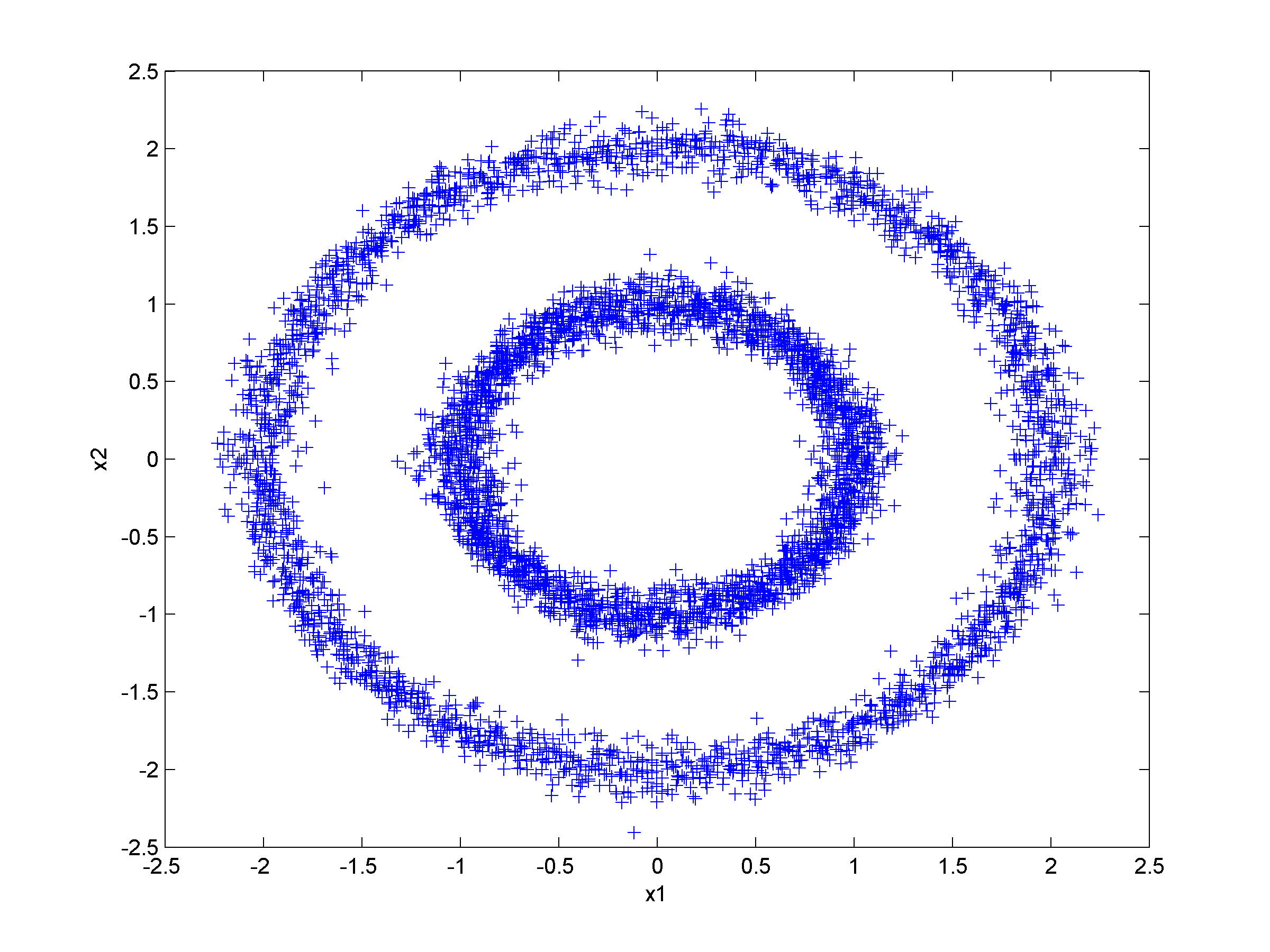
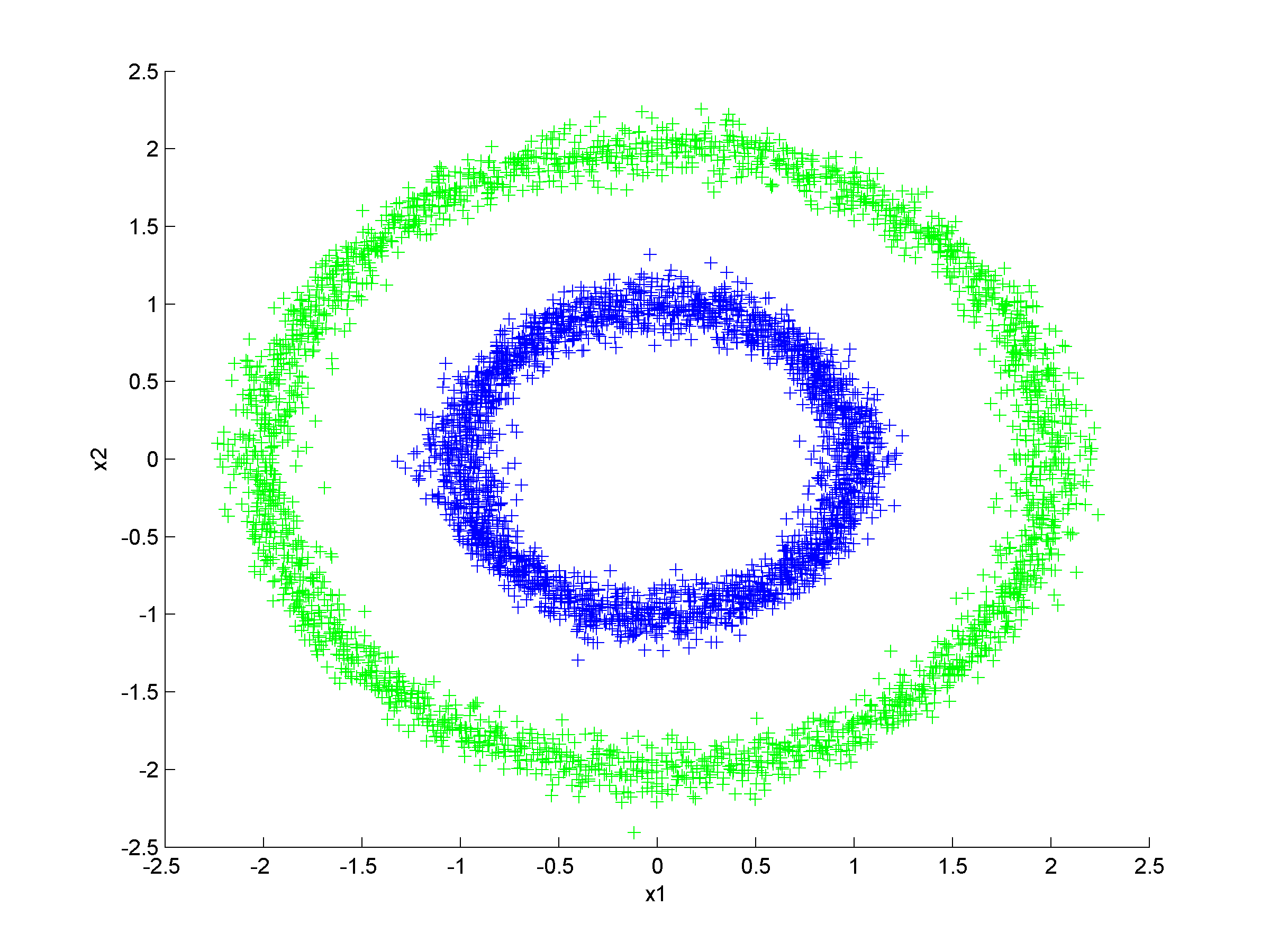
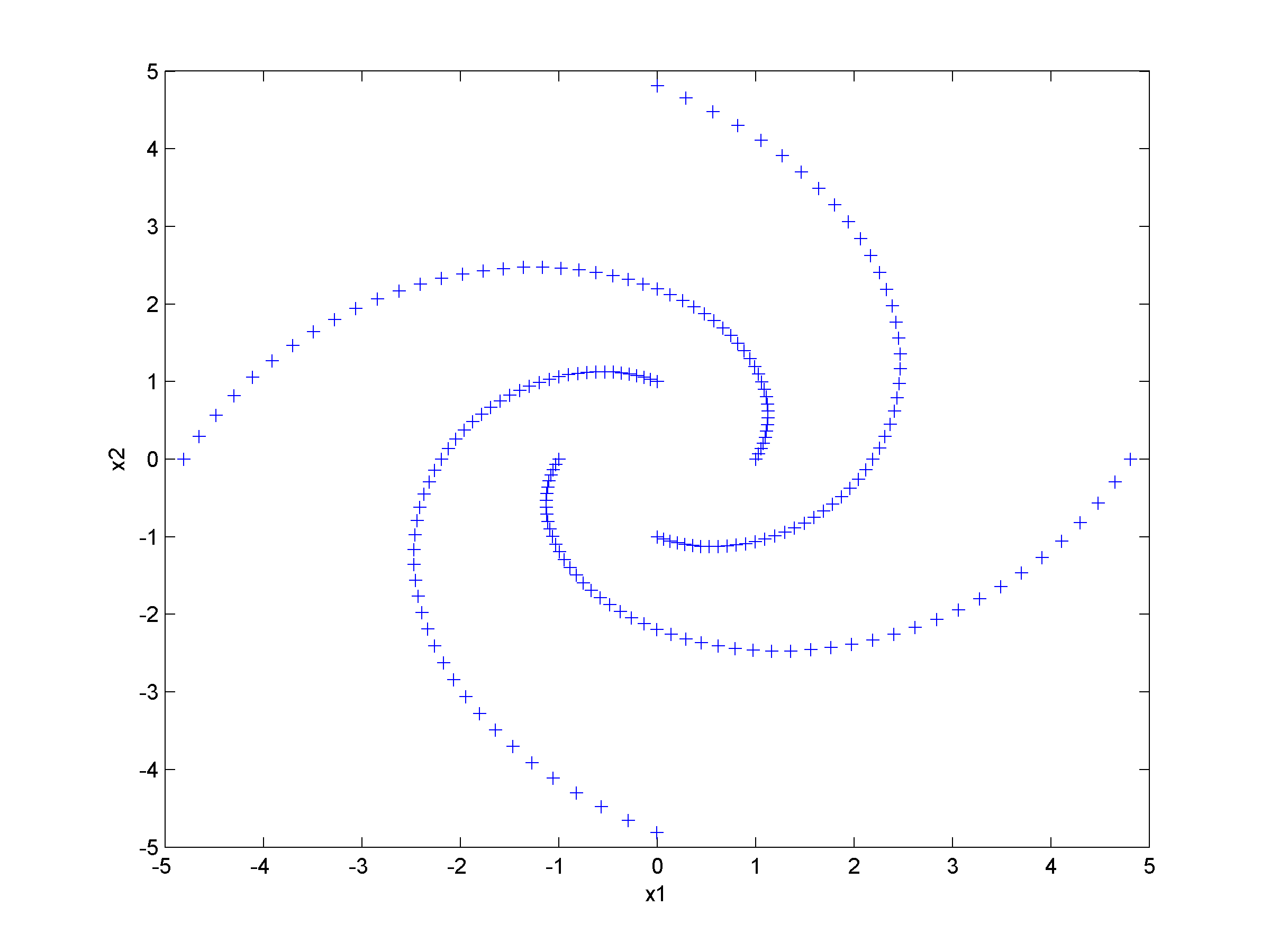
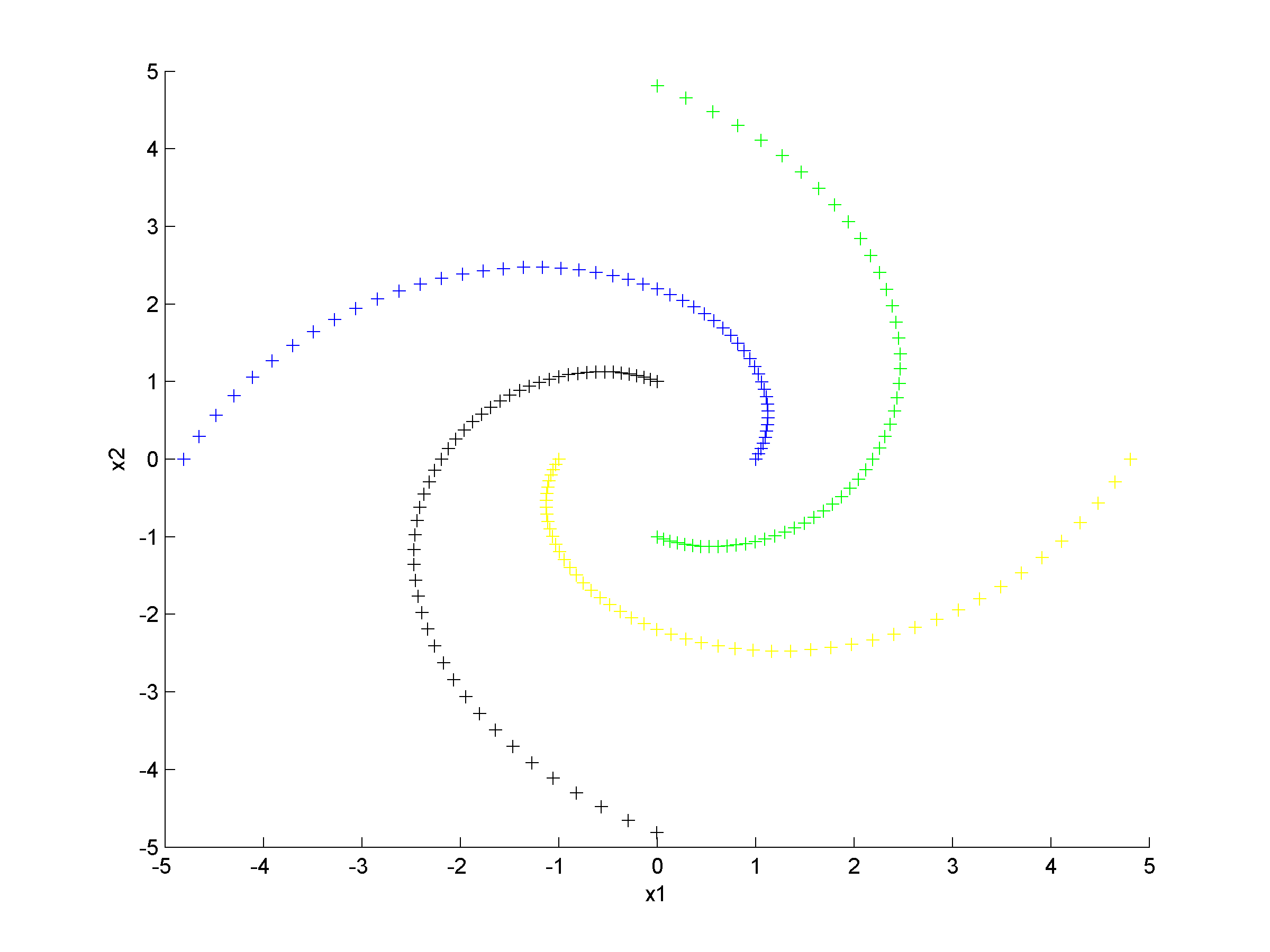
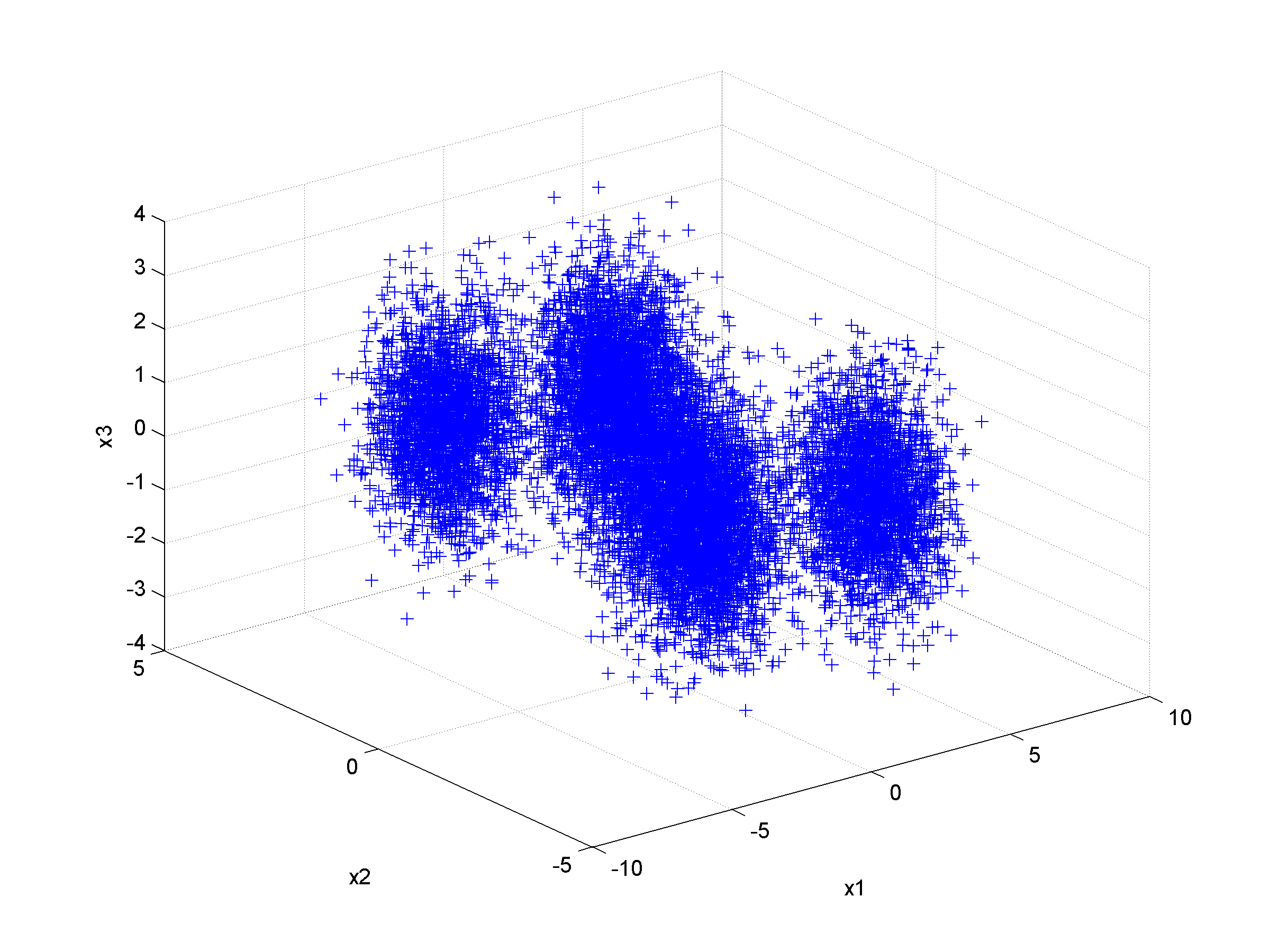
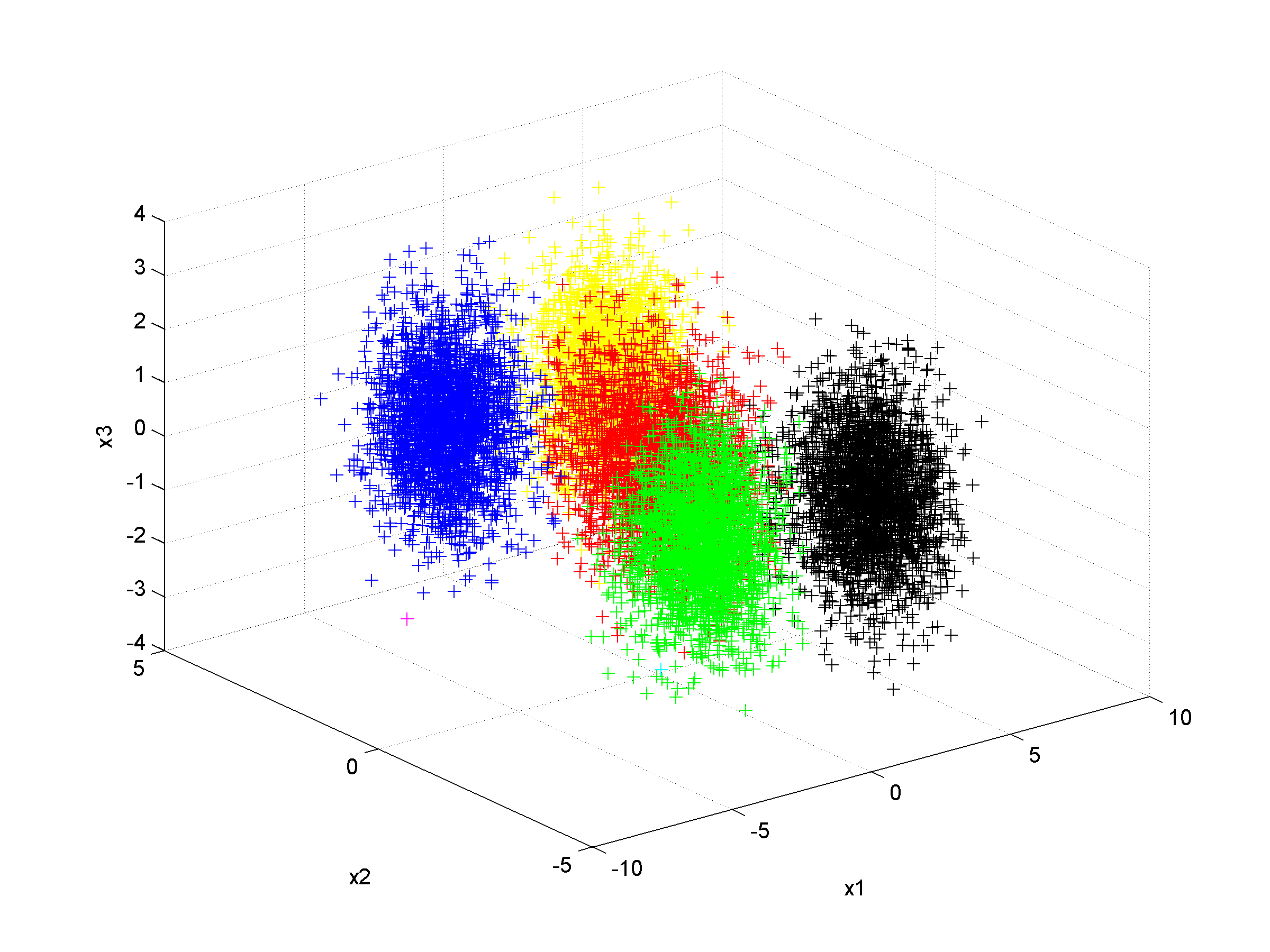
Unsupervised clustering using nearest neighbor likelihoodNearest neighbor likelihood values are computed using a critical distance threshold. These nearest neighbor likelihood values are then used to identify level sets that are used to find data points that are far from points that have previously been clustered. In this context 'far' means outside the critical distance threshold. The first cluster is assumed to contain the most likely data point, which is used to start the algorithm, and approximate cluster centers are assigned as the most likely data point in each cluster. Singleton clusters and isolated clusters containing a small number of points are frequently found. These may be removed or assigned to the closest cluster.
|
For information send email to:
info@biometricsnw.com
Last Update:
October 20, 2024
Copyright 2005-2024 Biometrics Northwest LLC